











Daftar Isi
- Menelusuri Evolusi teknologi AI suara dan speech-to-text mutakhir
- Komponen inti dalam teknologi AI suara dan speech-to-text mutakhir
- Bagaimana cara kerja teknologi AI suara dan speech-to-text mutakhir?
- Contoh penerapan teknologi AI suara dan speech-to-text mutakhir di dunia nyata
- Teknologi pendukung: dari cloud ke edge
- Strategi mengoptimalkan model speech-to-text untuk perangkat mobile
- Tren terbaru dalam teknologi AI suara dan speech-to-text mutakhir
- Tips memilih solusi speech-to-text yang tepat untuk bisnis Anda
- Masa depan teknologi AI suara dan speech-to-text mutakhir
Perkembangan kecerdasan buatan (AI) dalam beberapa tahun terakhir memang luar biasa. Dari gambar yang bisa diubah menjadi lukisan hingga chatbot yang terasa seperti manusia, semua itu menandakan betapa cepatnya teknologi bergerak. Salah satu bidang yang paling terasa dampaknya adalah pengenalan suara, khususnya teknologi AI suara dan speech-to-text mutakhir. Bagi siapa pun yang pernah berbicara dengan asisten virtual, menulis pesan lewat dictation, atau mendengar subtitle otomatis, Anda sudah merasakan manfaatnya.
Namun, di balik kemudahan yang tampak, ada sekian banyak komponen teknik yang bekerja keras: model deep learning, data pelatihan berukuran terabyte, serta optimasi perangkat keras yang membuat proses konversi suara menjadi teks berlangsung dalam hitungan milidetik. Artikel ini akan mengupas tuntas tentang teknologi AI suara dan speech-to-text mutakhir—dari sejarah singkat, arsitektur model, hingga aplikasi nyata yang mengubah cara kita berinteraksi dengan perangkat.
Menelusuri Evolusi teknologi AI suara dan speech-to-text mutakhir

Jika kita menengok ke awal 2000-an, sistem pengenalan suara masih bergantung pada teknik Hidden Markov Models (HMM) yang memerlukan fitur akustik manual seperti MFCC (Mel Frequency Cepstral Coefficients). Hasilnya? Akurasi yang masih cukup rendah, terutama pada bahasa dengan intonasi kompleks. Kemudian, kedatangan jaringan saraf tiruan (Neural Networks) membuka era baru, namun masih terbatas oleh kapasitas komputasi.
Lonjakan terbesar terjadi ketika deep learning masuk ke panggung. Model seperti Deep Speech (Baidu) dan Wave2Vec (Facebook) mengubah paradigma: alih-alih mengekstrak fitur secara manual, mereka belajar langsung dari data mentah. Pada tahun 2020-an, arsitektur transformer—yang awalnya dirancang untuk pemrosesan bahasa alami (NLP)—mulai diadaptasi untuk audio, menghasilkan model yang lebih cepat, lebih akurat, dan mampu memahami konteks panjang.
Komponen inti dalam teknologi AI suara dan speech-to-text mutakhir
- Encoder‑Decoder berbasis Transformer: Mengubah gelombang suara menjadi representasi vektor, lalu menerjemahkannya ke teks.
- Self‑Supervised Learning: Memanfaatkan data tak berlabel untuk melatih model, mengurangi kebutuhan dataset berlabel yang mahal.
- Quantization & Pruning: Teknik mengoptimalkan ukuran model sehingga dapat dijalankan di perangkat mobile atau edge.
- Multilingual & Code‑Switching: Kemampuan mengenali banyak bahasa sekaligus, termasuk perpindahan bahasa dalam satu kalimat.
Bagaimana cara kerja teknologi AI suara dan speech-to-text mutakhir?
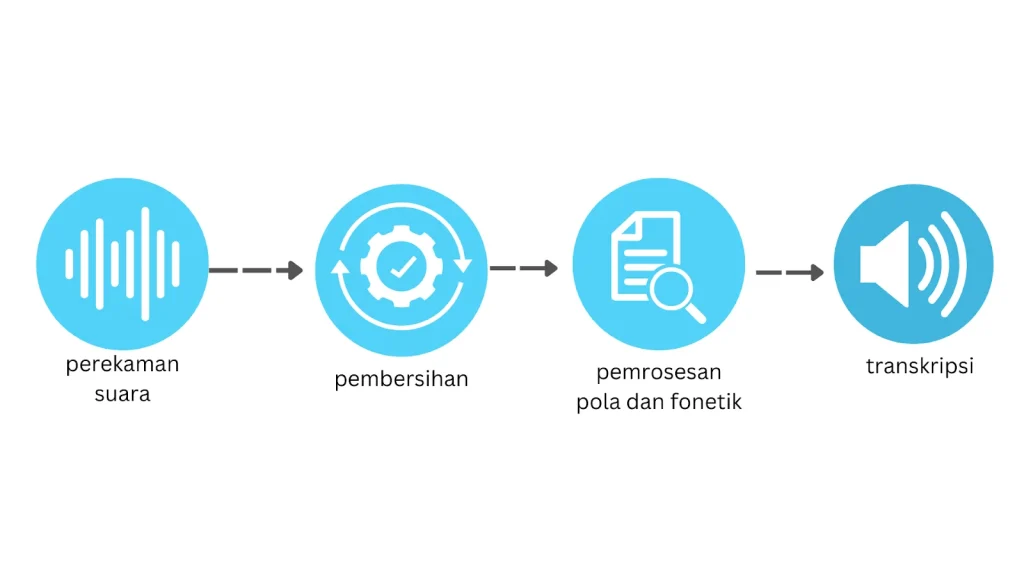
Pertama, sinyal audio masuk melalui mikrofon dan diubah menjadi serangkaian sampel digital. Selanjutnya, proses pre‑processing seperti normalisasi volume dan penghilangan noise dilakukan. Pada tahap ini, model teknologi AI suara dan speech-to-text mutakhir mengekstrak fitur spektral menggunakan jaringan konvolusional (CNN) atau blok mel‑spectrogram.
Fitur-fitur tersebut kemudian dilewatkan ke encoder transformer yang mengubahnya menjadi urutan vektor berdimensi tinggi. Di sini, self‑attention memungkinkan model “melihat” seluruh konteks audio sekaligus, sehingga dapat membedakan antara kata yang terdengar mirip tetapi memiliki arti berbeda. Decoder kemudian menghasilkan urutan karakter atau token teks, biasanya dengan algoritma beam search untuk memaksimalkan kemungkinan urutan yang paling masuk akal.
Semua langkah tersebut berlangsung dalam milidetik berkat akselerator AI khusus, seperti Tensor Processing Units (TPU) atau GPU berbasis CUDA. Inilah kenapa aplikasi voice assistant terasa hampir seketika, meski di baliknya ada proses komputasi yang kompleks.
Contoh penerapan teknologi AI suara dan speech-to-text mutakhir di dunia nyata
- Asisten Virtual: Siri, Google Assistant, dan Alexa mengandalkan model speech-to-text untuk mengubah perintah lisan menjadi teks yang dapat diproses.
- Transkripsi Otomatis: Platform seperti Otter.ai atau Rev.com menyediakan transkripsi real‑time untuk rapat, kuliah, dan konten video.
- Interaksi dalam Mobil: Sistem infotainment modern memungkinkan pengemudi mengirim pesan atau mengatur navigasi tanpa melepaskan tangan dari setir.
- Accessibility: Teknologi ini membuka peluang bagi penyandang disabilitas pendengaran untuk menikmati konten audio melalui subtitle otomatis.
Teknologi pendukung: dari cloud ke edge
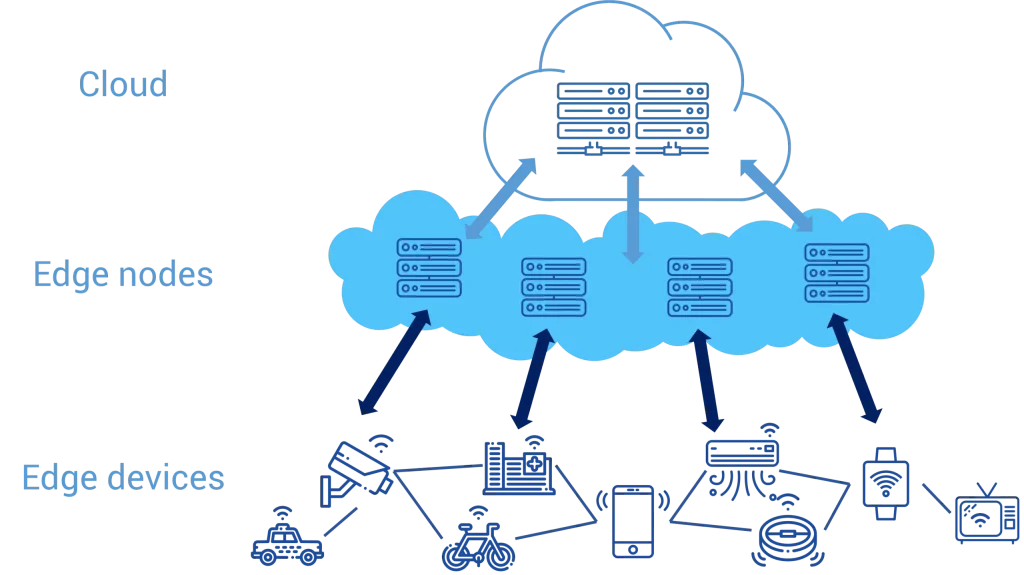
Salah satu tantangan utama dalam teknologi AI suara dan speech-to-text mutakhir adalah latensi. Mengirim data audio ke server cloud, memprosesnya, lalu mengirim balik hasilnya memerlukan waktu dan koneksi internet yang stabil. Untuk mengatasi hal ini, banyak perusahaan mengadopsi strategi hybrid: model ringan dijalankan di perangkat (edge), sementara model besar tetap di cloud untuk tugas yang memerlukan akurasi ekstra.
Contoh konkret adalah penggunaan on‑device inference pada smartphone Android atau iOS. Apple, misalnya, mengintegrasikan model speech-to-text langsung ke dalam sistem operasi, sehingga perintah “Hey Siri” dapat diproses tanpa harus terhubung ke server. Bagi developer yang ingin mengintegrasikan kemampuan serupa ke dalam aplikasi, ada banyak toolkit seperti Cara Mengintegrasikan AI dengan Aplikasi Mobile: Panduan Lengkap untuk Developer yang memberikan langkah‑langkah praktis.
Strategi mengoptimalkan model speech-to-text untuk perangkat mobile
- Model Distillation: Mengurangi ukuran model dengan melatih model kecil (student) meniru perilaku model besar (teacher).
- Quantization: Mengubah bobot dari 32‑bit float ke 8‑bit integer tanpa kehilangan akurasi signifikan.
- Dynamic Batching: Menggabungkan beberapa permintaan menjadi satu batch untuk efisiensi komputasi.
Tren terbaru dalam teknologi AI suara dan speech-to-text mutakhir

Berikut beberapa arah perkembangan yang sedang menggebrak industri:
- Zero‑Shot Multilingual Models: Model yang dapat mengenali bahasa yang belum pernah dilatih sebelumnya, hanya dengan sedikit contoh.
- Emotion Recognition: Mengidentifikasi nada emosional (senang, marah, sedih) dari suara untuk meningkatkan interaksi manusia‑mesin.
- Real‑Time Captioning untuk Live Streaming: Solusi yang dapat menambahkan subtitle otomatis pada video langsung dengan akurasi tinggi.
- Privacy‑First Architectures: Enkripsi end‑to‑end dan pemrosesan lokal untuk melindungi data suara pengguna.
Jika Anda penasaran dengan bagaimana AI generatif memengaruhi bidang lain, lihat Nvidia tunjukkan performa AI generatif terbaru – Insight Mendalam untuk perspektif yang lebih luas.
Tips memilih solusi speech-to-text yang tepat untuk bisnis Anda
- Evaluasi Akurasi vs. Latensi: Jika aplikasi Anda memerlukan respons instan (misalnya, asisten di mobil), pilih solusi edge yang lebih cepat meskipun akurasinya sedikit lebih rendah.
- Perhatikan Dukungan Bahasa: Pastikan model mendukung bahasa dan dialek target pasar Anda.
- Integrasi API: Pilih penyedia yang menawarkan SDK dan dokumentasi lengkap, seperti yang dibahas dalam Perbedaan model AI ChatGPT vs Google Gemini untuk developer – Panduan Lengkap.
- Keamanan Data: Pastikan data audio dienkripsi dan tidak disimpan tanpa izin.
Masa depan teknologi AI suara dan speech-to-text mutakhir

Ke depan, kita dapat mengharapkan integrasi yang lebih dalam antara pengenalan suara dan generasi bahasa alami. Bayangkan sebuah sistem yang tidak hanya mengubah suara menjadi teks, tetapi juga memahami niat di balik kata-kata, menyesuaikan respons berdasarkan konteks, dan bahkan menambahkan elemen visual seperti diagram atau gambar secara otomatis. Kombinasi ini akan membuka pintu bagi aplikasi kolaboratif yang benar-benar real‑time, seperti rapat virtual yang langsung menghasilkan notulen terstruktur dan aksi‑item.
Selain itu, kemajuan dalam hardware—seperti chip AI khusus untuk audio (Edge TPU, Apple Neural Engine)—akan semakin mengurangi kebutuhan akan koneksi internet, menjadikan teknologi ini lebih inklusif untuk daerah dengan infrastruktur jaringan terbatas. Dengan terus berkembangnya standar open source (misalnya, Whisper dari OpenAI), komunitas developer juga dapat berkontribusi memperbaiki model, menambah dukungan bahasa, dan menciptakan solusi yang lebih terjangkau.
Tak dapat dipungkiri, teknologi AI suara dan speech-to-text mutakhir sudah menjadi bagian tak terpisahkan dari ekosistem digital modern. Dari penggunaan harian di smartphone hingga integrasi kompleks di sektor kesehatan, pendidikan, dan bisnis, potensinya masih terus meluas. Jika Anda ingin tetap berada di depan kurva, penting untuk terus memantau perkembangan model, hardware, serta kebijakan privasi yang mengatur data suara.
Jadi, apakah Anda siap memanfaatkan kekuatan suara dalam produk atau layanan Anda? Dengan pengetahuan yang tepat dan alat yang mendukung, perjalanan Anda menuju inovasi berbasis suara dapat dimulai hari ini.



