










Daftar Isi
- Memahami cara kerja OpenAI ChatGPT: Dari Data ke Respons
- Detail cara kerja OpenAI ChatGPT dalam menghasilkan teks
- 1. Pengumpulan Data: Pondasi Pengetahuan
- 2. Pre‑training: Mengajarkan Bahasa kepada Model
- 3. Fine‑tuning: Menyulap Model Menjadi Chatbot
- 4. Reinforcement Learning from Human Feedback (RLHF): Penyempurnaan Berbasis Penilaian Manusia
- Arsitektur Model: Transformer dan Variannya
- Proses Inferensi: Dari Prompt ke Jawaban
- Keamanan dan Etika dalam cara kerja OpenAI ChatGPT
- Perbandingan dengan Kompetitor: ChatGPT vs Google Gemini
- Aplikasi Praktis dari cara kerja OpenAI ChatGPT
- Tips Mengoptimalkan Interaksi dengan ChatGPT
- Masa Depan dan Inovasi Lanjutan
Chatbot berbasis kecerdasan buatan kini sudah menjadi bagian tak terpisahkan dari kehidupan digital kita. Dari membantu menjawab pertanyaan sederhana hingga menulis esai kompleks, ChatGPT milik OpenAI menjadi contoh paling menonjol yang sering disebut dalam perbincangan teknologi. Namun, banyak orang masih penasaran: apa sebenarnya yang terjadi di balik layar ketika Anda mengetik sebuah pertanyaan dan mendapatkan respons yang terasa “manusiawi”?
Artikel ini akan mengupas tuntas cara kerja OpenAI ChatGPT secara detail, namun tetap dengan bahasa yang mudah dicerna. Kami akan menelusuri perjalanan data dari tahap pengumpulan, proses pelatihan model, hingga teknik penyempurnaan seperti Reinforcement Learning from Human Feedback (RLHF). Selain itu, Anda juga akan menemukan hubungan antara teknologi ini dengan tren AI lainnya, misalnya persaingan ChatGPT dengan Google Gemini.
Jika Anda tertarik melihat bagaimana AI percakapan ini dapat memengaruhi dunia kerja, Anda bisa membaca Apakah AI Mengancam Pekerjaan Manusia di Masa Depan? Analisis Lengkap. Mari kita mulai mengupas cara kerja OpenAI ChatGPT dari dasar hingga tingkat lanjutan.
Memahami cara kerja OpenAI ChatGPT: Dari Data ke Respons
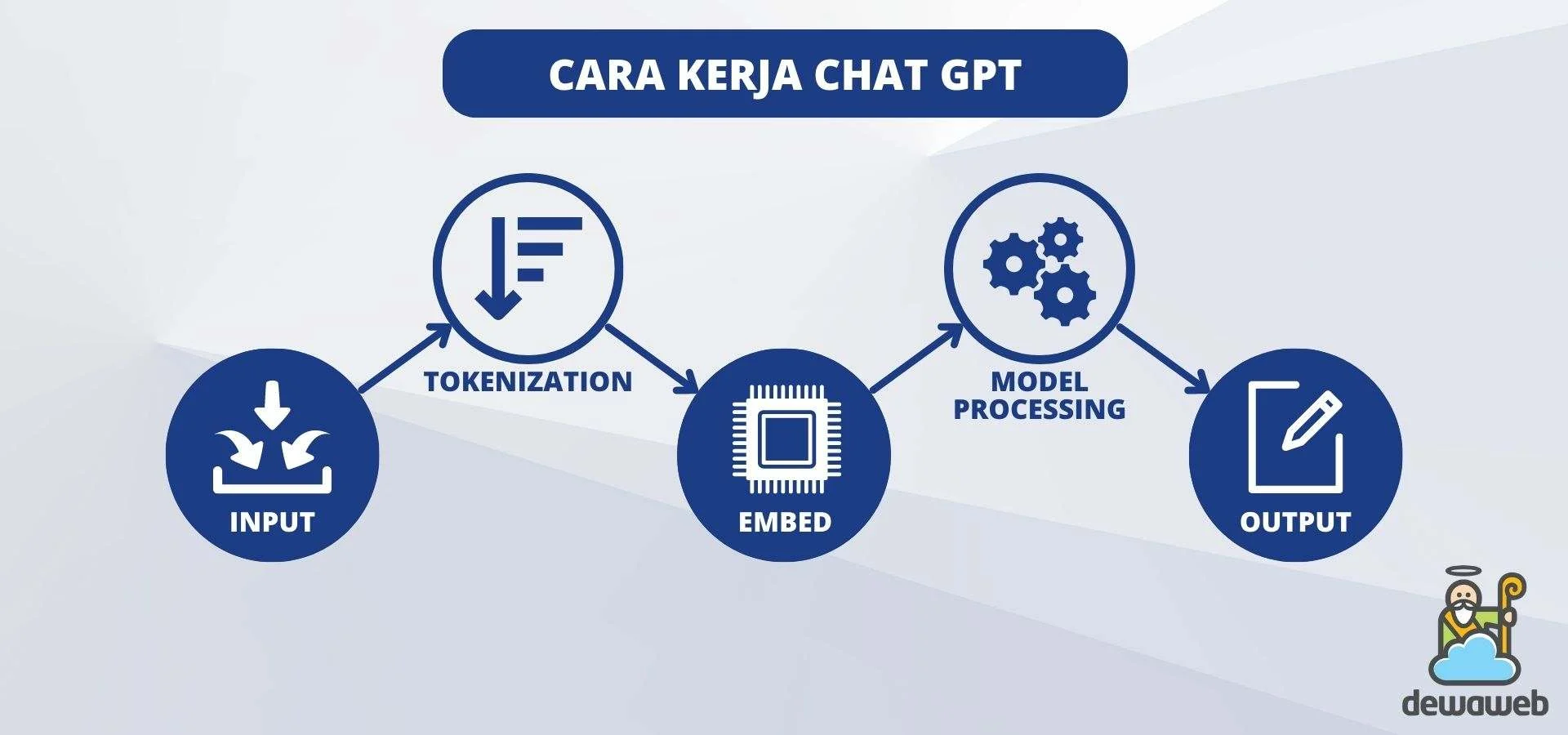
Sebelum masuk ke detail teknis, penting untuk menyadari bahwa cara kerja OpenAI ChatGPT bukan sekadar “menulis kode”. Ia melibatkan serangkaian tahapan yang saling berinteraksi, mulai dari kumpulan data teks yang sangat besar, arsitektur jaringan saraf yang canggih, hingga proses penyempurnaan berbasis umpan balik manusia.
Detail cara kerja OpenAI ChatGPT dalam menghasilkan teks
Berikut adalah rangkaian utama yang membentuk cara kerja OpenAI ChatGPT:
- Pengumpulan Data (Data Collection): ChatGPT dilatih dengan miliaran token teks yang diambil dari internet, buku, artikel, dan sumber lain yang berlisensi.
- Pre‑training (Pra‑pelatihan): Model belajar memprediksi kata selanjutnya dalam sebuah kalimat, menguasai struktur bahasa dan pengetahuan umum.
- Fine‑tuning (Penyetelan Lanjutan): Setelah pre‑training, model disesuaikan dengan dataset dialog khusus agar lebih responsif dalam percakapan.
- Reinforcement Learning from Human Feedback (RLHF): Manusia menilai kualitas respons, dan model diperbaiki melalui algoritma penguatan.
Setiap langkah ini berkontribusi pada kualitas output yang dihasilkan ChatGPT. Berikut penjelasan lebih mendalam.
1. Pengumpulan Data: Pondasi Pengetahuan
Data adalah bahan baku utama bagi cara kerja OpenAI ChatGPT. Tim OpenAI mengumpulkan teks dari berbagai sumber, termasuk Wikipedia, forum, buku, dan situs web publik. Data ini kemudian dibersihkan—menghapus konten duplikat, spam, atau materi sensitif.
Proses ini penting karena kualitas data menentukan seberapa baik model dapat memahami konteks dan menghasilkan jawaban yang relevan. Misalnya, jika dataset mencakup banyak contoh percakapan teknis, ChatGPT akan lebih terampil menjawab pertanyaan tentang pemrograman.
2. Pre‑training: Mengajarkan Bahasa kepada Model

Setelah data siap, model menjalani pre‑training menggunakan arsitektur Transformer yang diperkenalkan oleh Vaswani et al. (2017). Transformer mengandalkan mekanisme “self‑attention”, memungkinkan model memperhatikan seluruh kata dalam satu kalimat secara simultan.
Selama pre‑training, model berusaha memprediksi token berikutnya berdasarkan token sebelumnya. Dengan miliaran iterasi, model belajar pola bahasa, fakta umum, serta hubungan logis antar konsep.
3. Fine‑tuning: Menyulap Model Menjadi Chatbot

Setelah pre‑training, model masih bersifat “umum”. Untuk menjadikannya chatbot, OpenAI melakukan fine‑tuning dengan dataset dialog khusus. Dataset ini berisi contoh percakapan antara “pengguna” dan “asisten”. Tujuannya agar model belajar format pertanyaan‑jawaban dan menyesuaikan gaya bahasa.
Fine‑tuning juga mencakup prompt engineering, yaitu memberi instruksi khusus kepada model, misalnya “Berikan jawaban singkat dan jelas”. Teknik ini membantu mengarahkan model agar menghasilkan respons yang lebih terkontrol.
4. Reinforcement Learning from Human Feedback (RLHF): Penyempurnaan Berbasis Penilaian Manusia

Bagian yang paling menarik dari cara kerja OpenAI ChatGPT adalah penggunaan RLHF. Berikut langkah-langkahnya:
- Pengumpulan Respons: Model menghasilkan beberapa jawaban untuk satu pertanyaan.
- Penilaian Manusia: Pengulas (human labelers) menilai kualitas tiap respons berdasarkan kriteria seperti kebenaran, kejelasan, dan keamanan.
- Model Reward: Penilaian tersebut diubah menjadi fungsi “reward” yang memberi nilai numerik pada setiap respons.
- Optimasi Kebijakan: Menggunakan algoritma Proximal Policy Optimization (PPO), model diperbarui untuk memaksimalkan reward, sehingga menghasilkan jawaban yang lebih baik.
RLHF memungkinkan ChatGPT belajar dari preferensi manusia secara langsung, menjadikannya lebih aman dan relevan. Ini juga menjawab kekhawatiran tentang “bias” dan “konten berbahaya”.
Arsitektur Model: Transformer dan Variannya

Model ChatGPT dibangun di atas varian Transformer yang disebut “GPT” (Generative Pre‑trained Transformer). Versi terbaru (misalnya GPT‑4) memiliki lebih banyak lapisan (layers) dan parameter (hingga ratusan miliar), sehingga kapasitasnya jauh melampaui generasi sebelumnya.
Setiap lapisan Transformer terdiri dari dua komponen utama:
- Self‑Attention: Menghitung bobot perhatian antara setiap token, memungkinkan model memahami konteks panjang.
- Feed‑Forward Neural Network: Mengolah informasi yang telah di‑attention untuk menghasilkan representasi yang lebih tinggi.
Dengan menumpuk banyak lapisan, model dapat menangkap pola bahasa yang sangat kompleks, seperti ironi, metafora, atau logika berurutan.
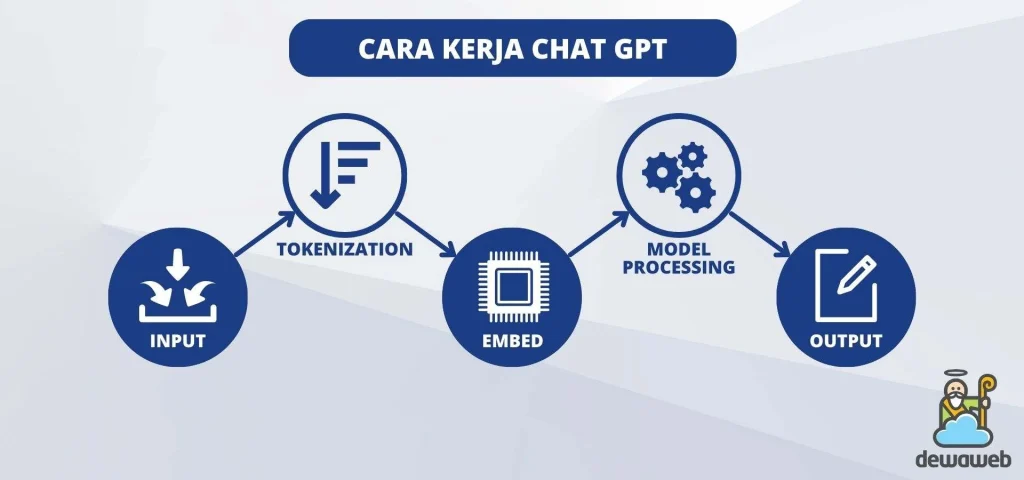
Proses Inferensi: Dari Prompt ke Jawaban

Setelah semua pelatihan selesai, inilah saat cara kerja OpenAI ChatGPT benar‑benar terlihat oleh pengguna. Proses inferensi (penyajian jawaban) melibatkan langkah-langkah berikut:
- Tokenisasi: Teks input diubah menjadi token (biasanya sub‑kata) menggunakan tokenizer Byte Pair Encoding (BPE).
- Pemrosesan Melalui Model: Token-token ini dilewatkan melalui jaringan Transformer untuk menghasilkan distribusi probabilitas pada token selanjutnya.
- Sampling / Decoding: Algoritma seperti Top‑k, Top‑p (nucleus sampling), atau beam search dipilih untuk menentukan token mana yang akan dipilih.
- Detokenisasi: Token yang terpilih diubah kembali menjadi teks yang dapat dibaca manusia.
Selama proses ini, parameter model (bobot) tidak berubah; hanya data yang mengalir melalui jaringan untuk menghasilkan prediksi.
Keamanan dan Etika dalam cara kerja OpenAI ChatGPT
OpenAI menaruh perhatian besar pada aspek keamanan. Selain RLHF, mereka menerapkan “content filters” dan “guardrails” yang memblokir jawaban yang mengandung hate speech, informasi berbahaya, atau pelanggaran privasi.
Jika Anda ingin mengeksplorasi tantangan keamanan AI, terutama dalam konteks militer, bacalah Risiko Keamanan AI dalam Sistem Militer: Apa yang Perlu Diketahui. Artikel tersebut memberikan perspektif yang menarik tentang bagaimana teknologi serupa dapat disalahgunakan.
Perbandingan dengan Kompetitor: ChatGPT vs Google Gemini
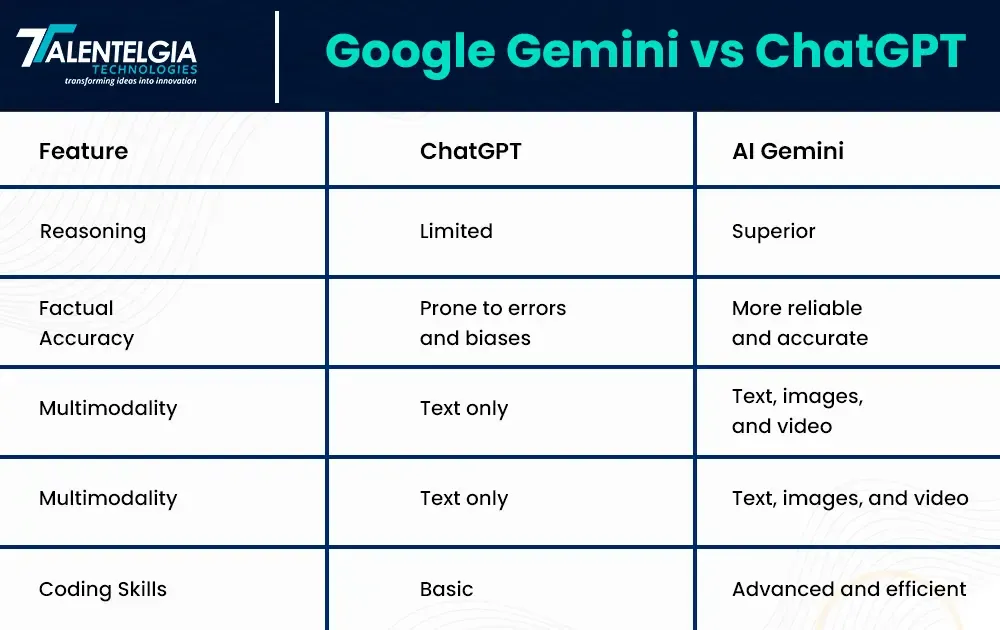
Persaingan dalam dunia AI percakapan semakin ketat. Masa Depan AI Percakapan: ChatGPT vs Google Gemini mengulas kelebihan dan kekurangan masing‑masing model. Meskipun arsitektur dasar keduanya serupa, perbedaan utama terletak pada data pelatihan, strategi fine‑tuning, dan kebijakan keamanan.
Aplikasi Praktis dari cara kerja OpenAI ChatGPT
Berbagai industri sudah memanfaatkan cara kerja OpenAI ChatGPT untuk meningkatkan produktivitas:
- Layanan Pelanggan: Bot otomatis menjawab pertanyaan umum, mengurangi beban tim support.
- Pendidikan: Membantu siswa menulis esai, memberikan penjelasan konsep, atau menyediakan latihan bahasa.
- Pengembangan Konten: Penulis dapat menggunakan ChatGPT untuk brainstorming ide, menulis draft, atau menyunting teks.
- Analisis Data: Dengan plugin khusus, ChatGPT dapat membantu menganalisis dataset dan menuliskan laporan secara otomatis. Lihat contoh pada Tutorial AI untuk Analisis Data: Panduan Praktis dan Lengkap.
Tips Mengoptimalkan Interaksi dengan ChatGPT

Supaya Anda mendapatkan jawaban yang paling relevan, perhatikan beberapa kiat berikut:
- Berikan prompt yang jelas dan spesifik. Contoh: “Jelaskan perbedaan antara supervised learning dan unsupervised learning dalam 3 kalimat.”
- Gunakan role‑playing bila diperlukan, misalnya “Anda adalah seorang dosen ekonomi, jelaskan …”.
- Jika respons tidak memuaskan, coba ulang dengan penyesuaian atau tambahkan konteks tambahan.
- Manfaatkan parameter
temperature(jika tersedia) untuk mengatur tingkat kreativitas; nilai rendah = lebih fokus, nilai tinggi = lebih kreatif.
Masa Depan dan Inovasi Lanjutan
OpenAI terus mengembangkan teknologi di balik ChatGPT. Rencana berikutnya mencakup:
- Model Multimodal: Mengintegrasikan teks, gambar, dan audio dalam satu model.
- Peningkatan Efisiensi: Mengurangi kebutuhan komputasi dengan teknik sparsity dan quantization.
- Personalisasi: Memungkinkan pengguna meng‑tune model pada data pribadi mereka dengan cara yang aman.
Dengan inovasi ini, cara kerja OpenAI ChatGPT diprediksi akan semakin mendekati interaksi manusia‑mesin yang alami dan aman.
Kesimpulannya, memahami cara kerja OpenAI ChatGPT memberikan kita gambaran jelas tentang bagaimana AI modern dapat belajar, beradaptasi, dan berinteraksi dengan cara yang hampir menyerupai manusia. Dari kumpulan data yang masif, arsitektur Transformer, hingga proses RLHF yang melibatkan penilaian manusia, setiap komponen berperan penting dalam menghasilkan respons yang akurat, relevan, dan bertanggung jawab.
Jika Anda tertarik mengeksplorasi lebih jauh tentang AI generatif, jangan lewatkan artikel Aplikasi AI Generatif dalam Konten Digital: Tren & Peluang. Semoga penjelasan ini membantu Anda memahami seluk‑beluk teknologi yang sedang mengubah cara kita berkomunikasi secara digital.



